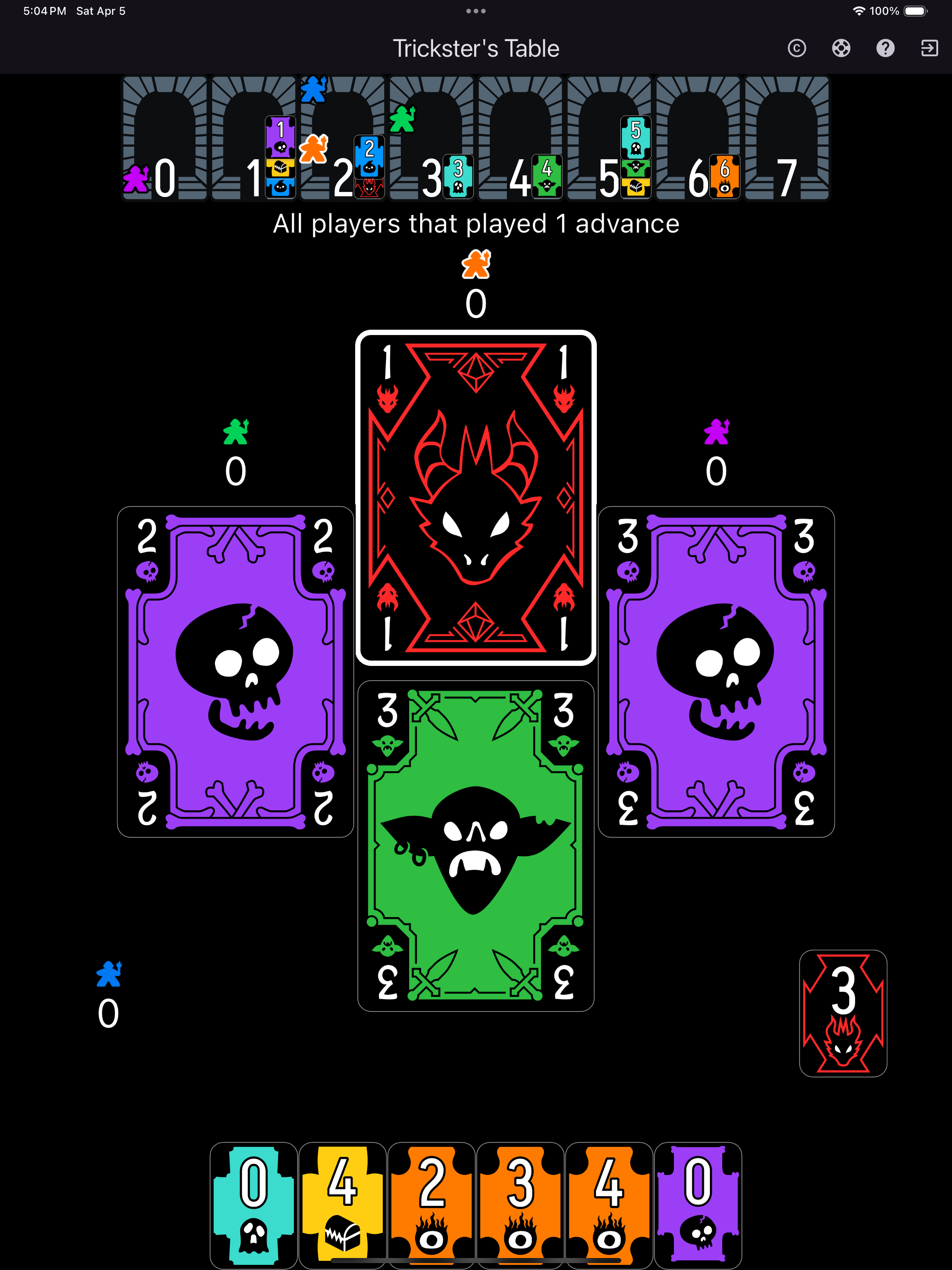
Trickster's Table
Dart
Flutter
Rust
Python
A gamut of 17 supporter-selected trick-taking card games with challenging but fair AI opponents. 100% free. No microtransactions. No addiction loops. No ads. Just pure and simple card games.
Find out moreA gamut of 17 supporter-selected trick-taking card games with challenging but fair AI opponents. 100% free. No microtransactions. No addiction loops. No ads. Just pure and simple card games.
Find out more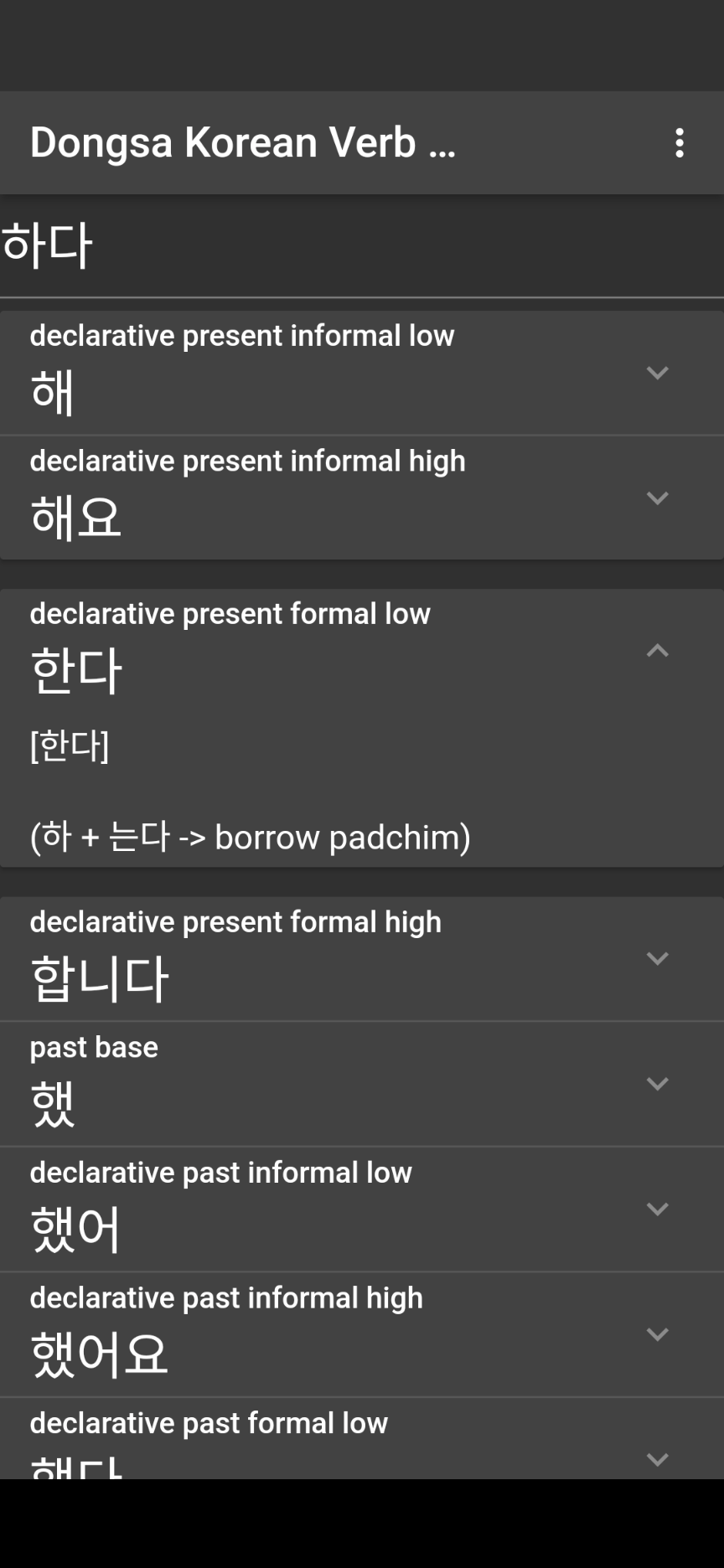
Master Korean verb conjugations with detailed explanations of grammar rules and pronunciation. Available as a web app and mobile application.
Try It
Build your Korean vocabulary by learning the Korean pronunciation of Chinese characters (Hanja). A powerful tool for intermediate to advanced learners.
Explore