I have been reading and watching a lot of reviews about what had become the board game that made it to the top of my w84.it list. It is a pretty pricey game and I only budget $1.66 for non-essential items like video games and board games a day so I had about 20 days to wait before I could get my hands on it. After reading the rules I decided it wouldn't be too hard to repurpose some components from other games to try it out. We just happened to have enough colored cubes from other games and the player mats were simple enough that after about 20 minutes of work I had everything set up. Sooyeon and I played a game and we were both very underwhelmed. That meant that the money I had been saving for this game could be used on something else so I picked up a video game that was next on my list. It was cheaper and much more fun than the board game turned out to be.
This is the idea behind w84.it a web and Android application I have worked on for the past few weekends. Psychologists have learned through studies that seeing representations of the things you desire helps you wait for them longer. Having a list helps you get to cool/slow/rational thinking as opposed to hot/fast/impulsive thinking. The checkout lanes of grocery stores are essentially gauntlets of temptation, lined with impulse purchase items like candy and tabloid magazines. The same happens frequently online when you are bombarded with advertisements for things they know you want. The good news is that you can train yourself to control your impulses and be more mindful and deliberative about what you want to spend your money on. w84.it was built with that goal in mind. If you find yourself really wanting something you just found out about you can add it to your list and then compare it with the other things you had been planning on getting for a while. w84.it helps you keep a budget and avoid buyer's remorse.
If you are interested in trying it please head to w84.it or download the Android app. I would appreciate any feedback you have.
With only one week left before the release of Super Mario Odyssey I have been watching every video I can of the gameplay and it has left me severly jonesing for the platforming challenges that Mario games can provide. The in-store demos of Mario Odyssey are great but I have spent over 3 hours on the demo and it was starting to feel like Groundhog Day since you have to restart after 10 minutes from the beginning of Tostarena. The other day I decided to go back and replay Mario Galaxy 2 to get my fix and I have not been disappointed. There is an incredible amount of variety and creativity that is packed into Super Mario Galaxy 2. Every level feels so unique and challenging in a good way. Yesterday, in co-op mode my daughter and I beat a level where we had to guide a Chain Chomp head across some train tracks while being chased by a collection of Cosmic Mario Clones who repeat your every move until they catch up to you. My daughter stopped the Chain Chomp at just the right time so I could cause platforms to rise and fall at just the right time so the Chain Chomp wouldn't hit a wall and disintegrate so he could make it to his final destination where we were rewarded with a star. If you somehow missed Mario Galaxy 2 and have a Wii or Wii U do yourself a favor and pick it up. It's a masterpiece that has received a score of 97 on Metacritic.
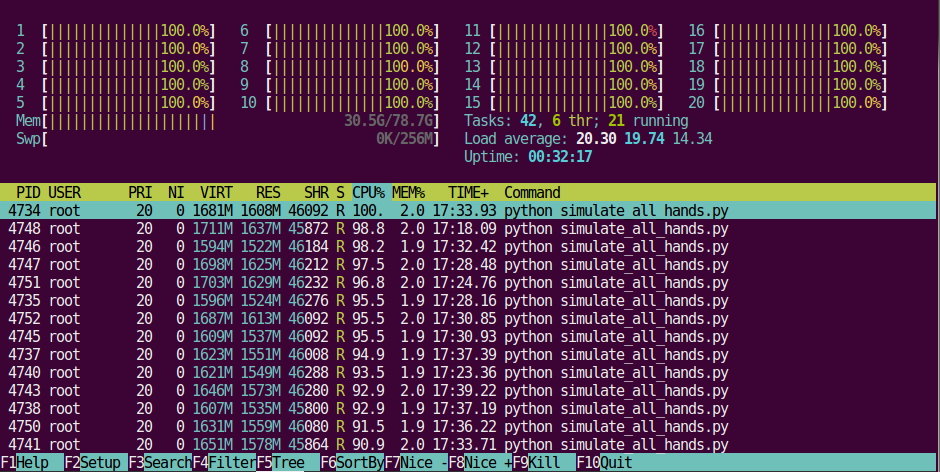
Over Memorial Day weekend I took my toy Euchre AI that plays using Information Set Monte Carlo Tree Search and ran it on a VPS with 20 CPUs and recorded the first level of child nodes (which presumably contained all the best moves). There are 42,504 (24 choose 5) Euchre hands. To cut down on computations required I actually skipped hands that had the same set of "outside" cards the second time they were encountered and filled in the details from the previous run that had the same outside cards (with the suits swapped). This reduced the possible number of hands from 42,504 to 22,398. I kept track of each unique hand based on trump (which for the simulations I always kept as hearts) and diamonds (because the distribution of cards in the suit with the same color as trump is different because the jack of the same color becomes the left bower). But for these outside hands I assumed the results would be the same. For example if you have an outside ace and 10 in one suit and and outside jack and queen in the other suit your chances of winning are the same either way.
Monte Carlo Tree Search is a very simple algorithm. In order to use it you need to implement the game rules including a method that returns legal plays that can be made given a game state. MCTS searches the game tree depth-first which means it plays games over and over again to completion from the state it started with. Each time it visits a node where not all the moves have been tried it randomly picks a move it has not yet tried. (This step can be made smarter if you add some heuristics and/or deep learning to prune out suboptimal moves.) If all the moves have been tried it uses an equation to choose which play it should try next. This equation weighs how often it should exploit plays that have led to wins and how often it should explore other moves that appeared to be less optimal but might only have appeared that way.
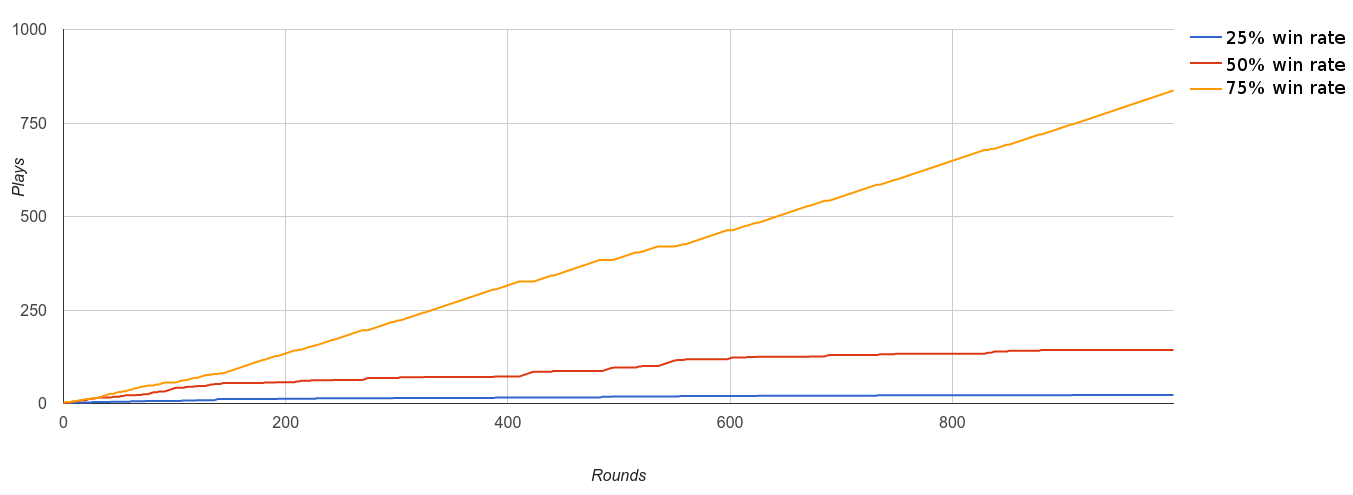
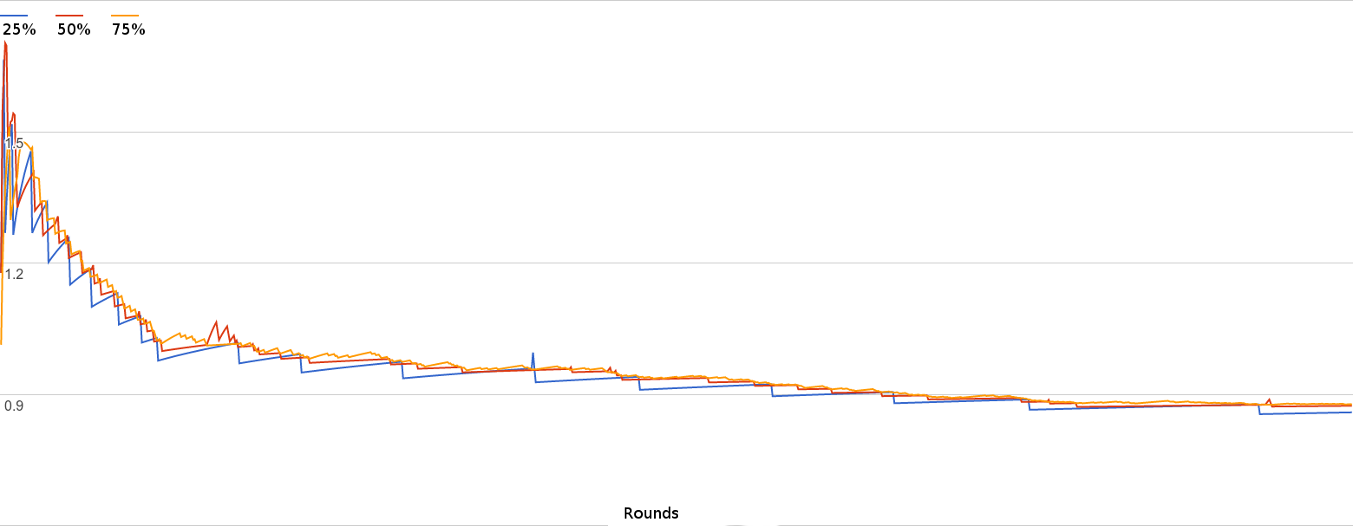
In order to better understand this equation, called UCT (Upper Confidence Bound 1 applied to Trees), I simulated a game with moves that had a fixed win rate and then graphed the results. The game I simulated is very simple - it has 3 moves. The orange move wins 75% of the time, red 50% and blue 25%. The visits graph is straightforward. UTC exploits the orange (75% win rate) move more often than the red (50% win rate) move and it exploits the blue (25% win rate) move the least:
Here is the graph of the UCT values for that same simulation. You can see how it is chaotic at first but then as it figures out that the orange move has a high win rate it visits it more than the others but still checks in with them occasionally.
Once its allotted number of runs is done MCTS returns the most visited node as the move to make.
Since Euchre is a game with hidden information I used Information Set Monte Carlo Tree Search which is just a little more complicated than vanilla MCTS. Since you can't be sure which cards your opponents will have for each simulation you randomly distribute cards based on the possible hands a given player could have based on their past play history. So, for example, if a player trumped on spades during the hand their hand must not contain spades (since no cheating is allowed in the simulation).
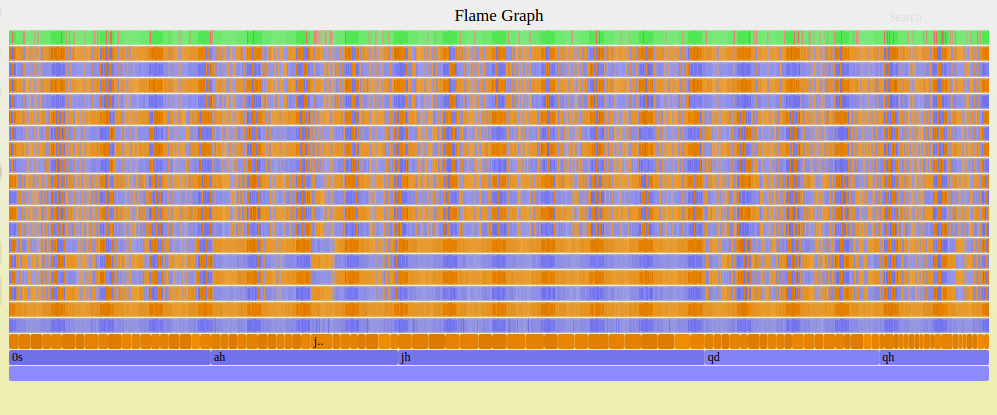
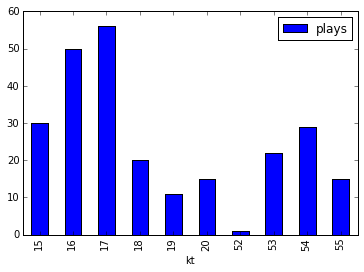
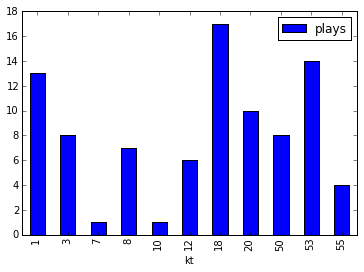
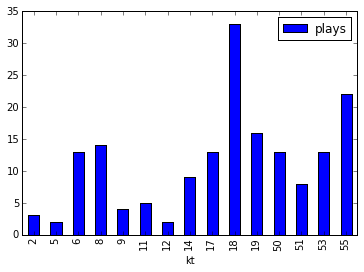
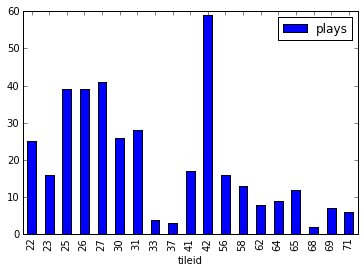
Here is an example graph from a sample run (with just 1,000 plays) of the Euchre simulation:
The width of each node represents the number of times it was visited. So for this hand the jack of hearts was the most chosen card and the simulation would choose to play this card first. A green bar in the final row at the top indicates that the blue team (the computer's team) won and a red bar indicates that they lost. This is a strong hand so it wins a lot.
It took about 200 CPU hours (20 CPUs times 10 hours) to complete the simulation for all possible hands though about half way through I realized I had an issue where multiple workers might be working on the same hand so I started writing a flag to to the database before workers took their randomly selected hand. It would have been much better to do this with a queuing system. I love queues so I'm not sure why I did it the way I did - just wanted to keep things simple I guess.
Some random pictures of what was happening on the machine and some random numbers:
22,398 de-duplicated hands
(out of 42,504 total hands)
223,980,000 total simulations
(10,000 per hand)
1,119,900,000 total tricks
(5 per simulation)
720,000 CPU seconds
(10 hours)
1555 tricks per second
311 hands per second
15.5 hands per second per core
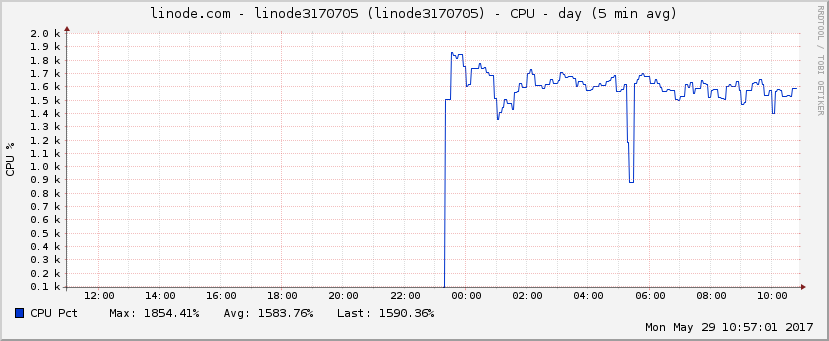
I got this notice right after I started the simulation (well before 2 hours had passed):
Your node has exceeded the notification threshold (90) for CPU Usage by averaging 1597.0% for the last 2 hours.
To be honest 311 hands per second across 20 cores is pretty pathetic (or my math could be totally wrong). Either way I probably could have made it much more efficient if I put some effort into profiling and optimizing before running this experiment. Catching the potential duplicate work issue faster would have also probably decreased the overall time.
To sanity check the database I looked through a bunch of the top search results for card leading strategies in Euchre. A lot of this strategy deals with situations that this simulation wasn't aware of, like whether or not your partner called up trump. It just starts in a situation where trump is known and everyone has 5 cards to play and it has the lead. One article in particular had some great advice that seems to line up with the database:
Generally speaking, it's worth leading the right bower here if you have it. Yes, you may theoretically be stepping on your partner's left bower, but you can't know for sure, and if you are long in trump then it's a good idea to guarantee yourself this trick, as well as more remaining trump than anyone else at the table.
Lead with a singleton off-suit ace, if you have one. A singleton ace is a strong lead for two reasons. First of all, if no other cards of that suit are in your hand, there is a higher probability that they are in your opponents' hands, preventing them from trumping your ace. Your best chance for an ace to make it around the table and win a trick is on the opening lead.
Pay special attention to the "next" suit, the same-color suit as trump. Since the left bower switches suits, this suit only has five cards, and thus even if you hold only an ace and one other card in that suit, leading the ace will often be an invitation for your opponents to trump you.
In this case, save your ace for later and hope it can win a trick once trump is all drawn out.
So I paid about 10 dollars to run a 20 core VPS for 10 hours to be just a little bit more confident that what we already knew about Euchre was correct. Ah well - it was fun nonetheless. Maybe someone else can find more interesting information in the database. It's available on GitHub. And you can query it on euchredb.bravender.net.
React Native is pretty amazing. I started getting excited about frontend development again when React came out and now that you can use the same concepts to create native mobile interfaces. Here is a video from a puzzle game I'm working on:
Sooyeon and I have been playing the Castles of Burgundy (CoB) a lot recently. We play it in real life and also on online at Yucata. Sooyeon often beats me so I wanted to figure out what I was doing wrong by looking at some of the better players on Yucata and analyzing their games.
I'm not going to spell out how the game works here. If you are unfamiliar with the game I would recommend checking out the rule book and maybe even some BoardGameGeek reviews of the game.
The data I used consists of 1,742 games from the top 20 rated players on Yucata.de.
Boards
There has been a lot of discussion about the power of each of the player boards and an analysis of board usage on boite-a-jeux. Board 8 was found to be so overpowered that Yucata doesn't allow it anymore. It was only used in 19 games in the data set. I'll start my analysis with the boards that have been used in the data set I have.
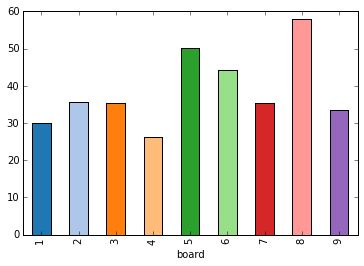
Overall board usage
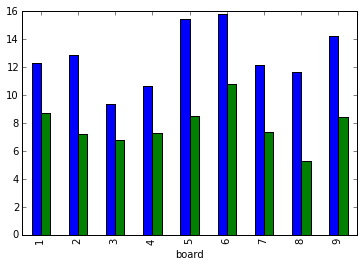
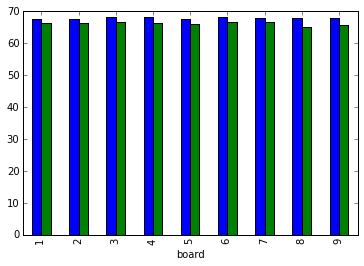
Boards 5, 1 and 6 are the most popular among the top 20 players on Yucata.
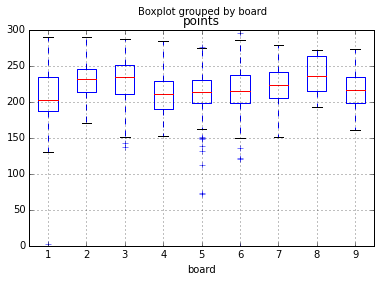
Board win rate
The board with the highest win rate is the notorious banned board 8 followed by 5 and then 6. (Sooyeon's favorite board is 7 by the way.)
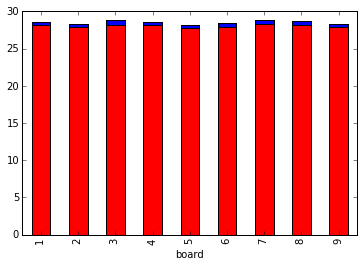
Points possible from regions per board
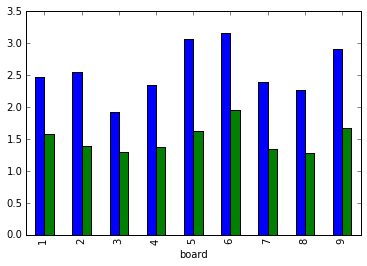
Each board has its own set of region sizes. These are the maximum theoretical bonus points you could get just by filling each region of a board (I'm not sure if it's possible to fill in every region in a game against a mildly competent opponent).
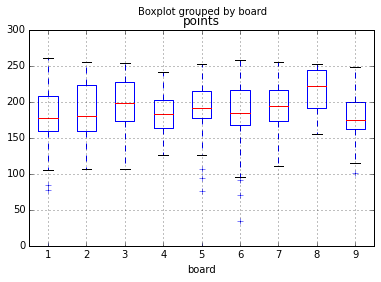
Winner points by board
Runner-up points by board
Turn order in COB can change each round depending on the position of ships which players can advance. Going first lets you take tiles you want or your opponent needs before other players.
Overall first turns
Winners take more first turns than runners up on average.
First turns at the start of a phase
Board 6 has all blue spaces connected which might explain why players using it are able to go first so often (you can always play a boat if you get one whereas on the other boards you might need to expand before you can play a boat).
Actions
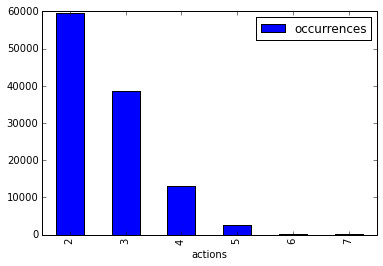
Some tiles in CoB (Castles, Carpenter's Workshops, City Halls and Churches) give you the ability to take extra actions. You can also take an extra purchase action once per turn. The maximum number of actions seen was 7 but it is extremely rare (it only happened 6 times in the 114,074 turns that were made).
Occurrences of action count
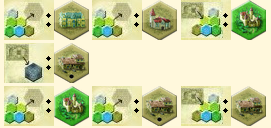
7-action turn example
play City Hall
[bonus] play Church
[bonus] take Castle
purchase Carpenter's Workshop
play Castle
[bonus] play Carpenter's Workshop
[bonus] take Carpenter's Workshop
Actions per turn winners vs. runners up
Winners take 1.43342472817 more actions than the runner-up in a game. It doesn't look like there is a significant action advantage for any particular board.
Average tiles played winners vs runners up
Winners play 0.426907452706 more tiles than runners up on average.
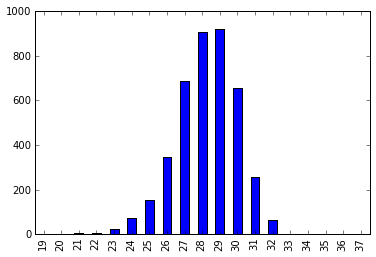
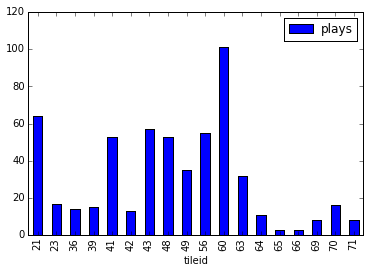
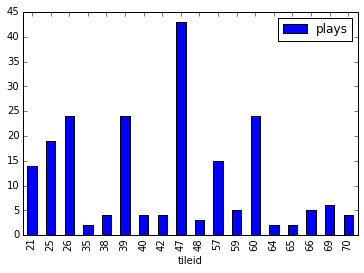
Placed tiles distribution
The most tiles that were seen played was 32 (out of 37 spaces).
Tiles played breakdown
Note that the tile code in Yucata is different than the number on the tiles themselves.
Knowledge tiles
2-player knowledge tiles played by winner - times played by runner up
3-player knowledge tiles played by winner - times played by runner up
4-player knowledge tiles played by winner - times played by runner up
Other tiles
2-player tiles played by winner - times played by runner up
3-player tiles played by winner - times played by runner up
4-player tiles played by winner - times played by runner up
Unfortunately it turned out to be really difficult to find out how many points came from each action since points are recorded per turn instead of per action and points from knowledge tiles are earned the turn when the effects of the knowledge tile take place and are not recorded separately in the game data. I believe this is all happening on the server so calculating how many points were earned by each action would require essentially reimplementing the game (but it would be awesome data).
Having worked on six e-commerce websites (half of which make millions of dollars in revenue every year) I can safely say that downtime is a sure fire way to upset the business side of any company. Time, after all, is money. I've worked with teams that have tried minimizing downtime incurred by releases in many different ways. Here are some of the extremes:
On one end of the spectrum you can avoid downtime during deployments by only deploying during maintenance windows. The downside here is pretty obvious - what if the release introduces a bug and you don't find out about it until during a peak traffic period? I've seen people throw their hands in the air and say "I guess our customers can't use functionality X and will get that error until we can deploy tomorrow morning" in shops where this was the way deployments were done. I've also had a front row seat when a site I was working on was brought down for an emergency deployment and we were inundated with customer complaints.
The other side of the spectrum I've seen tried is blue/green phoenix deployments - rebuilding each and every VM with the same software but a new version of the application. After testing is done on the new VMs you can cut over either a hardware switch or software like HAProxy so it points to the new version. Needless to say using this method takes a very long time if all you want to do is deploy a one line fix. If you aren't familiar with blue/green deployments be sure to check out Martin Fowler's article about them.
There is a Goldilocks solution to this problem which won't take down a site and won't take as long as a full blue/green phoenix deployment. That said, as with all technical solutions, it isn't without its own drawbacks and might not be right for all deployments.
Here is the ridiculously simple Flask application I'll be deploying as an example:
The updates in deploy should be idempotent (that is to say that you can run deploy multiple times and the result should be the same each time (except for the pids of the workers that are started)). One tricky bit here when you are harnessing git for your deployments is that you want to clean up your remote working copy. I didn't do this in the example but you can use git clean to make sure only the things in the repository end up in the working copy. I did this with Python but you can substitute any language that doesn't require a binary build step and has a way of installing isolated packages. I guess it could be done with Ruby and RVM. I also have a nodejs example in the gitric repository.
The directory structure that gets built out looks like this:
├── blue
│ ├── env
│ ├── etc
│ └── repo
├── green
│ ├── env
│ ├── etc
│ └── repo
├── live -> /home/test-deployer/bluegreenmachine/green
└── next -> /home/test-deployer/bluegreenmachine/blue
To do the initial build-out all you need is an automator user on your remote server and an nginx host entry set up something like this:
server {
listen 80;
server_name server.name.here;
location / {
include /home/test-deployer/bluegreenmachine/live/etc/nginx.conf;
}
}
server {
listen 80;
server_name next.server.name.here;
location / {
include /home/test-deployer/bluegreenmachine/next/etc/nginx.conf;
}
}
Then you can run
fab prod deploy
fab prod cutover
These steps are intentionally separated so you can check the next environment before cutting over to the new release.
I cut over to a new release while running ab and continuously hitting the server with curl to see what the server was returning:
% ab -c 100 -n 5000 http://my.server.here/
This is ApacheBench, Version 2.3 <$Revision: 1528965 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking my.server.here (be patient)
Completed 500 requests
Completed 1000 requests
Completed 1500 requests
Completed 2000 requests
Completed 2500 requests
Completed 3000 requests
Completed 3500 requests
Completed 4000 requests
Completed 4500 requests
Completed 5000 requests
Finished 5000 requests
Server Software: nginx/1.4.1
Server Hostname: my.server.here
Server Port: 80
Document Path: /
Document Length: 28 bytes
Concurrency Level: 100
Time taken for tests: 33.180 seconds
Complete requests: 5000
Failed requests: 2576
(Connect: 0, Receive: 0, Length: 2576, Exceptions: 0)
Total transferred: 922576 bytes
HTML transferred: 142576 bytes
Requests per second: 150.69 [#/sec] (mean)
Time per request: 663.607 [ms] (mean)
Time per request: 6.636 [ms] (mean, across all concurrent requests)
Transfer rate: 27.15 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 164 326 87.5 321 1393
Processing: 161 308 188.7 284 4045
Waiting: 161 307 186.5 284 4045
Total: 338 635 216.9 646 4409
Percentage of the requests served within a certain time (ms)
50% 646
66% 675
75% 689
80% 699
90% 723
95% 758
98% 789
99% 899
100% 4409 (longest request)
My server is the tiniest VM Linode offers and I'm on the other side of the Earth from it so I'm not really concerned about the performance. I am checking that all the incoming requests were served while a release was deployed without any downtime. You can see that ab counted 2576 failing length requests - those aren't actually failures - ab counts different content from the initial response it receives as a failure and halfway through the load test I cut over to a new release:
% for x in $(seq 100); do curl -s -S http://my.server.here/ && echo; done
Hello 0-downtime blue World!
Hello 0-downtime blue World!
Hello 0-downtime blue World!
Hello 0-downtime blue World!
Hello 0-downtime blue World!
Hello 0-downtime blue World!
Hello 0-downtime blue World!
Hello 0-downtime blue World!
Hello 0-downtime blue World!
Hello 0-downtime blue World!
Hello 0-downtime blue World!
Hello 0-downtime blue World!
Hello 0-downtime blue World!
Hello 0-downtime blue World!
Hello 0-downtime blue World!
Hello 0-downtime blue World!
Hello 0-downtime blue World!
Hello 0-downtime blue World!
Hello 0-downtime blue World!
Hello 0-downtime blue World!
Hello 0-downtime blue World!
Hello 0-downtime blue World!
Hello 0-downtime green World!
Hello 0-downtime green World!
Hello 0-downtime green World!
Hello 0-downtime green World!
Hello 0-downtime green World!
Hello 0-downtime green World!
Hello 0-downtime green World!
Hello 0-downtime green World!
Hello 0-downtime green World!
Hello 0-downtime green World!
Hello 0-downtime green World!
Hello 0-downtime green World!
Hello 0-downtime green World!
Hello 0-downtime green World!
Hello 0-downtime green World!
Hello 0-downtime green World!
Hello 0-downtime green World!
Hello 0-downtime green World!
Hello 0-downtime green World!
Hello 0-downtime green World!
Hello 0-downtime green World!
Hello 0-downtime green World!
Hello 0-downtime green World!
Hello 0-downtime green World!
Hello 0-downtime green World!
Hello 0-downtime green World!
Hello 0-downtime green World!
The special sauce is leveraging the reload functionality that most webservers (Apache, nginx) offer. Existing workers are told that they should not handle new requests and the new workers that are spawned proxy all traffic to the new version. Here is a trace from my server right after a cutover:
nginx PID 29381 (labeled "nginx: worker process is shutting down") is handling an old request to the previous release and will shut down once it is finished. A request that came in after the release is going to port 8888 (the new release). All future requests will go to the new nginx workers which forward traffic to port 8888. These are the details of how nginx handles graceful reloads but a complete understanding this isn't necessary to harness the power of this deployment method.
Using git to deploy code for languages which don't require builds like Python and Ruby shortens the time it takes to build packages and deploy. I wrote about this a few years ago. Coupling that with blue/green deployment techniques on the same server has led to a very pleasant deployment experience for me and my team for the past year and a half. Everyone takes turns deploying and as our fleet of servers grows our deployment process won't get any slower now that we use the @parallel decorator during the update phase.
It takes a tiny extra amount of planning to write code and migrations that can be deployed without bringing down a live service but with experimentation and practice you will find that it is not that much work. This video from the Disqus team is an amazing resource. You should prefix your memcache keys with a short git ref and warm up your cache before cutting over. With Postgres you can usually add new tables and even add new NULL-default columns without problems but you'll definitely want to test your migrations on a staging environment which is simulating locked rows (if you use SELECT FOR UPDATE to ensure consistency). If you use a background worker like Celery tasks might linger from previous versions so you need to handle cases where the old API is called with a default:
If there is a scheduled process_order with the old function signature in the queue it could fail unless you give the new parameters you add default values. These are just a few of the caveats I could think of. Always test deployments and rolling back on staging when in doubt until you get the hang of it.
There are numerous reasons why you would want to deploy updates to an API or website without downtime using the blue/green deployment method:
Customer satisfaction - living and working on the other side of the world (Korea) I find it very frustrating that services I depend on to get my work done think that "maintenance hours" are in the middle of my day just because the sun has set on their side of the world.
You can roll back from bad releases without re-deploying - the old release is still there so you can cut back to it in case you find problems in the new release.
Ability to fix unforeseen problems quickly - should you determine that there is a problem which isn't large enough to warrant cutting back to the old release you can still deploy a fix even while there are thousands or millions of customers using your service without interrupting them.
You are one step closer to continuous deployment.
As I said above there are countless techniques that can be used to deploy software and they all have their trade-offs. OS-level packages can't be upgraded in isolation like virtualenv and the application can. Critics might say that this only works for language-level packages and not OS-level packages or even OS upgrades. I fully understand this point and I guess it's just a trade-off. The future looks very bright when it comes to techniques that provide even further isolation and faster deployments like docker and other similar projects. I look forward to using tools like this to make it so there is even less downtime on the projects I work on in the future. In the meantime this porridge is just right for the type of projects I'm working on.
Sooyeon and I have been very busy for the past 7 months with our brand new baby daughter Haereen. When I get a few spare seconds I still work on my personal projects but it's been pretty slow going as of late. I'm definitely not complaining since Haereen is totally worth it. Anyway, here is a summary of some of the things I've worked on in my free time.
dongsa.net 2.0 preview
dongsa.net is a Korean verb conjugation algorithm that explains the contractions and exceptional rules for many tenses and levels of politeness. The current version is written in Python but there was a whole rewrite of the engine into JavaScript over two years ago to make it easier to port to Android and iOS. I've had the rewrite sitting in a branch for around a year now but it's only been a month or so since I pushed up preview.dongsa.net.
This was made possible by Kyubyong Park graciously allowing me to use his database of English definitions of Korean verbs.
Stemmer - the new stemmer reverses the conjugation process. You can see how it works here. Basically, there is list of flattened out Korean verbs (so "춥다" is stored as "ㅊㅜㅂㄷㅏ". It goes through the flattened version of the conjugated form (say "추웠어요" -> "ㅊㅜㅇㅜㅓㅆㅇㅓㅇㅛ") that is passed in and strips one bit off at a time and looks for all verbs that match it. It requires that the verb is in the database and doesn't yet work for some forms of irregulars (ㄹ dropping verbs) but it's a start.
I've had these changes sitting in a branch for almost a year now. There are only a few items left on the todo list before I can switch dongsa.net over to this new version. The biggest todo item is to make it look better. I am clearly not a designer. If that's your thing and you want to help out I would greatly appreciate it.
When I was pointed to Python Deployment Anti-Patterns by a colleague I was a little shocked to see that the way we had been deploying applications with fabric and git over the past two years (over 1500 deployments) with no problems was being called an Anti-Pattern. There are definitely many ways to deploy software applications and they all have their pros and cons. Our process is by no means perfect but the way that we use git within fabric is definitely one of the best parts of our deployment process.
In his follow-up article Hynek made the case that deploying with native packages is better. On my team we actually started out deploying packages but since developers deploy we got sick of waiting for the packages to build and upload so we switched to git-based deploys. Packages are, of course, a valid way to deploy software, but I think the criticisms leveled against fabric git-based deploys might have been against doing these deploys in a specific way. I'm writing this article to show you how we have been successful using git-based fabric deployments.
I agree with many of his points:
"Don't use ancient system Python versions"
"Use virtual environments"
"Look into alternatives to Apache + mod_wsgi setups"
"Don't run your daemons in a tmux/screen"
Upstart is my personal favorite because it is very stable and the configuration is succinct. Here's an example of a daemon that I've had running on one of my personal projects for several years with no issues:
start on runlevel [12345]
stop on runlevel [0]
respawn
exec sudo -u www-data PATH=path/to/app VIRTUAL_ENV=path/to/virtual_env path/to/python_server_script
Why anyone would want to write a billion line init script now that upstart exists is beyond me. Perhaps they don't know about upstart. It could also be that they are stuck on CentOS or RedHat. My heart goes out to you if that's the case. I know how that feels.
Here are some of the points I disagree with:
Configuration is not part of the application
I've seen others make this same claim and on the face of it it makes sense up to a point. On my team developers deploy so we keep templates of configurations and the differences are kept in context variables that are passed into the templates. If there is sensitive information we keep it outside of version control. Really, if you want to test changes from dev through staging and onto production why not keep the configuration as similar as possible? On projects where teams are creating very generic apps that are being deployed with many different configurations I understand the need for this but most web application developers are deploying to a very specific target (production). It makes sense to keep your development settings as close to that target as possible. For example, if staging and production have the ENCRYPT_STUFF setting set to TRUE then your development environment should have it set too. But they should all have different keys and the production setting should be kept out of version control.
What's wrong with Fabric+git-pull?
It doesn't scale. As soon as you have more than a single deployment target, it quickly becomes a hassle to pull changes, check dependencies and restart the daemon on every single server. A new version of Django is out? Great, fetch it on every single server. A new version of psycopg2? Awesome, compile it on each of n servers.
Fabric will roll through all commands on all servers in a predictable manner one after the other. That way they can be taken out of the load balanced pool before the service is HUP'd and put them back in after it comes back. If this is done automatically with unattended package upgrades (as proposed later in the article) isn't there the possibility that all your servers become unavailable at the same time?
You should always run pip and if there is nothing to upgrade it will simply do nothing. There's no need to download all of the packages - you can have them seeded on each server before starting the upgrade.
It's hard to integrate with Puppet/Chef. It's easy to tell Puppet "on server X, keep package foo-bar up-to-date or keep it at a special version!" That's a one-liner. Try that while baby sitting git and pip.
I can't speak to integrating fabric with Puppet and Chef but it's basically a one-liner to update a remote target with fabric:
It can leave your app in an inconsistent state. Sometimes git pull fails halfway through because of network problems, or pip times out while installing dependencies because PyPI went away (I heard that happens occasionally cough). Your app at this point is – put simply – broken.
A git pull will not leave your app in an inconsistent state. If the network fails it won't change your working copy and fabric will stop the script because git will return an error. That said I don't think you should use git pull anyway since it is one more moving part that can fail during deployment and it requires that your private repository be open to the world. Since git is distributed a developer can push their repo's immutable store to the target using git push during deployment. Running git reset --hard [deployment-sha1] after the push is finished will update the working copy. Since there is a repo on the other end you'll only be sending the new objects since the last push to the target. This is why git-based deploys beat packages speed-wise. Most of our code deploys take a fraction of a second.
Even a private PyPI mirror can fail. Why not upload the packages to the target and run pip like this?
You could even store your packages in a git submodule and sync your submodules at the same time. (We sync submodules as well, it's only a little extra work.)
Weird race conditions can happen. Imagine you're pulling from git and at the same time, the app decides to import a module that changed profoundly since its last deployment. A plain crash is the best case scenario here.
When you install with a package you have to stop and restart the app. You need to do the same thing if you use git and fabric. With git, it takes much less time to update because only the modified files are swapped out. Packages copy whole trees of files many of which are most likely not modified between releases so the app will be down longer while this disk IO takes place.
Check out the gitric fabric module I wrote that performs git deployments in the way I've described above.
One other valid problem I've heard raised about git-based deploys is that you can end up with cruft in your working copy that sticks around like .pyc files where the original .py file is deleted and there is the chance that this file could still be imported even though the original .py was deleted. Since cloning a local git repository uses hard links you can seed your remote repository and then clone it locally on the same machine (even for slightly large projects this only takes a little extra time). Stop your server, move the old repository out of the way and move the new cloned repo where the old one was (or use a current symlink) and then restart the server.
Git-based deployments make sense for scripting languages where there isn't a compile step so the repo can be sent as-is to production (so it wouldn't make sense for a Java application). It's worth harnessing git to make deployments faster. If we only had to deploy once a month we might've settled for package-based deployments but we push often and got sick of waiting for packages to build and upload.
Packages are, of course, a legitimate way to push out changes but the downside of deploying with packages is that it takes time to build them and upload them
Git + fabric is suitable for deployments (my team has deployed using it over 1500 times)
git-based deployments are lightning fast to deploy and roll back
There is no build step
You only have to upload objects that have changed
Use git push, don't use git pull
It's one less moving part that can fail during deployment
You don't have to open your git repository to the world
You can pre-seed git's immutable object store without affecting your running application
You can have pip use local packages which are more reliable and you also avoid having to set up a PyPI mirror
Git has a lot of bells and whistles and there are a lot of different ways to achieve any given task. I've seen several workflow documents explaining how to use the staging area and git add --patch to only commit some of the changes in your working copy so you can keep nice clean logical commits. I love the idea of having a clean history and logical commits but I think there are some drawbacks to using the index as part of a normal workflow.
The problem with the staging area
I always want to commit working code (if possible) because I could switch to another task and I don't want to come back to broken code (or even worse - pass along broken code to a colleague). That's why I always try to commit all changes in my working copy. When you start getting fancy and using the index to commit partial changes your working copy and your index get out of sync and it's possible for your code to appear as though it's working when you are using it or running your tests but the code that you commit might not work. One thought-experiment example: it's possible to commit a new test but not the new function or method that the test is checking even though the test is passing. Whenever your tests or tools are running they are running against your working copy. Whenever you are running your code interactively you are exercising the code that is in the working copy. Your file system does not understand that you only have some chunks of your changes staged for a commit. When I want to remove in-progress or half-baked code I use (and recommend) git stash --patch. It is the opposite of git add --patch -- it removes changes interactively and creates a stash of the unfinished chunks of code. Like any other stash, the changes can be popped or applied later. Once you have removed the in-progress code you can run your tests and know that you are committing working code. Another benefit of patch stashing unfinished changes is that they become part of the immutable history which can be used as a backup for in-progress code.
There you have it. That's why I avoid the index and frequently use git stash --patch in my git workflow.
In Python (and most sane scripting languages) when something unexpected happens an exception is raised and execution stops. Damien Katz calls this the "Get the Hell out of Dodge" error handling method in his seminal Error codes or Exceptions? Why is Reliable Software so Hard?. In his article Damien explains several different ways of handling errors. None of the options is to ignore that something went wrong. That's because ignoring problems only makes them worse. But that's exactly what PHP and MySQL do for certain classes of errors.
Here's how Python handles failure:
% python
>>> print a
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'a' is not defined
>>>
PHP's default behavior is to just keep chugging along ignoring problems that could cause huge issues:
% php 2> >(while read line; do echo -e "stderr> $line"; done)
<?
printf("%d\n", $a);
?>
0
stderr> PHP Notice: Undefined variable: a in - on line 2
stderr> PHP Stack trace:
stderr> PHP 1. {main}() -:0
A "notice", eh? Really? If you try to delete a record from a database using sprintf to ensure it is a decimal and accidentally pass in an undefined variable as the id PHP will happily tell the database to delete the record with the id of "0". In my opinion this deserves more than a "notice" in the logs. PHP's default error-handling behavior is a recipe for disaster.
Fortunately, if you must use PHP, there is a way to make PHP behave in a more sane manner and force every unexpected event to raise an exception (exception_error_handler from http://www.php.net/manual/en/class.errorexception.php):
% php 2> >(while read line; do echo -e "stderr> $line"; done)
<?
function exception_error_handler($errno, $errstr, $errfile, $errline ) {
throw new ErrorException($errstr, 0, $errno, $errfile, $errline);
}
set_error_handler("exception_error_handler");
printf("%d\n", $a);
?>
stderr> PHP Fatal error: Uncaught exception 'ErrorException' with message 'Undefined variable: a' in -:7
stderr> Stack trace:
stderr> #0 -(7): exception_error_handler(8, 'Undefined varia...', '-', 7, Array)
stderr> #1 {main}
stderr> thrown in - on line 7
There is one huge problem with this. If you are building on an existing PHP project or have a ton of PHP code it's likely that you will see frequent breaks once you make failure the default. That's a direct result of the language designers choosing such lenient default behavior. If you are starting a new project using PHP you should get your head checked (see phpsadness.com). If you pass a psychological evaluation and you still for some reason want to build a new project using PHP you should turn on immediate failure by using the error handler mentioned above and write tests to exercise your code. You'll thank me later.
Now, let's look at default behaviors of some popular databases:
% psql
# create table simple_table (col varchar(10));
CREATE TABLE
# insert into simple_table (col) values ('1234567890a');
ERROR: value too long for type character varying(10)
% mysql
mysql> create table simple_table (col varchar(10));
Query OK, 0 rows affected (0.23 sec)
mysql> insert into simple_table (col) values ('1234567890a');
Query OK, 1 row affected, 1 warning (0.08 sec)
mysql> select * from simple_table;
+------------+
| col |
+------------+
| 1234567890 |
+------------+
1 row in set (0.00 sec)
Yup, by default MySQL just silently truncates your data. Ronald Bradford, a self-proclaimed MySQL Expert sums it up nicely: "By default, MySQL does not enforce data integrity." That should set off alarm bells in your head if you are using or considering using MySQL. The whole point of a database is to store valid data. The simple solution is to use a database that cares about your data like Postgres but if you must use MySQL you should set
PHP and MySQL are widely used. Maybe it is because their default settings are so lenient that it makes it easy for beginners to pick up. No one really cares if there was an error saving a hit on your personal homepage to your database. The problem is that these settings are not conducive to writing quality software. When starting from scratch it's better to choose technologies that have smarter defaults like Python and PostgreSQL because the libraries and software written using these technologies will properly fail instead of doing unexpected things and filling your database with garbage.
PS
You can (and should in most cases) also force hard failure for bash scripts by running set -e at the top of the script. See David Pashley's Writing Robust Shell Scripts for more.